Time Series to Images (Ts2Img)
The Ts2Img module transfers observations from a time series data set into an image stack. The advantage of the image format is, that all observations at a time can be loaded at once. The image format is therefore preferred over time series when loading data for large areas over a short time period.
Source and target grid
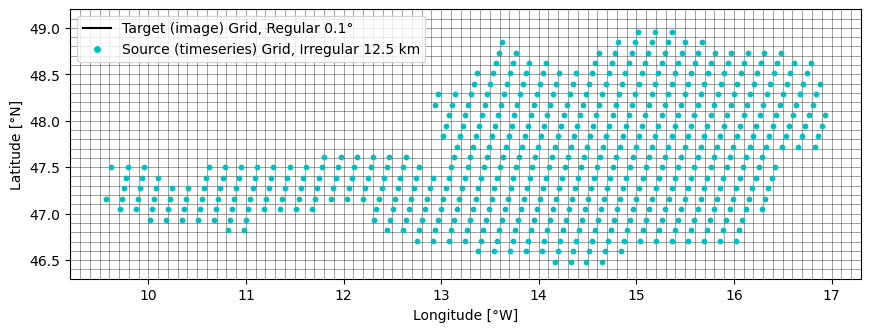
The following plot shows how the input data is organised spatially. Blue dots are locations where a time series in the source data set is available. The black raster are the pixels of the target grid cells (where we want to transfer the time series to).
For this example, the source grid is the subgrid for Austria of the 12.5 km WARP Grid (used for ASCAT soil moisture data). The target grid is a gap-free 0.1 degree regular raster.
[1]:
import os
from pygeogrids.grids import CellGrid
from pygeogrids.netcdf import load_grid
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
import numpy as np
from repurpose.process import rootdir
source_grid = load_grid(os.path.join(rootdir(), "docs", "examples",
"assets", "warp_subgrid_AUT.nc"))
y = np.arange(46.3, 49.2, 0.1)
x = np.arange(9.2, 17.4, 0.1)
z = np.full((y.size-1, x.size-1), np.nan)
plt.figure(figsize=(10.2,3.5))
plt.pcolormesh(x, y, z, edgecolors='k', linewidth=0.5, alpha=0.2)
plt.scatter(source_grid.activearrlon, source_grid.activearrlat, s=10, c='c')
plt.xlabel('Longitude [°W]')
plt.ylabel('Latitude [°N]')
legend = [Line2D([0], [0], color='k', label='Target (image) Grid, Regular 0.1°'),
Line2D([0], [0], marker='o', color='w', markerfacecolor='c',
label='Source (timeseries) Grid, Irregular 12.5 km')]
plt.legend(handles=legend, loc='upper left')
[1]:
<matplotlib.legend.Legend at 0x7ffab2bfae10>
Input time series
For this example we create a small timeseries reader class. Our time series are stored on the above shown “source grid”. Our dataset comprises a single csv file with soil moisture data for most of the source locations. Soil moisture values between 1st to 10th of June 2010 are provided in “docs/examples/assets/SM_AUT.csv”. The reader just finds the closest source point for a passed lon/lat pair and returns the according time series extracted from the csv file.
[10]:
import pandas as pd
class Reader:
def __init__(self):
self.df = pd.read_csv(
os.path.join(rootdir(), "docs", "examples", "assets", "SM_AUT.csv"),
index_col=[0, 1], parse_dates=True)
self.grid: CellGrid = source_grid
def read(self, lon, lat):
# The only relevant part is, that the reader has a function that takes a latitude and longitude
# and return a time series for the closest point.
gpi, _ = self.grid.find_nearest_gpi(lon, lat)
if gpi not in self.df.index.get_level_values(0):
return None
else:
return self.df.loc[gpi]
We can try this and plot of few time of the time series that we find close to some random points in the area. The reader wors as expected.
[11]:
source_reader = Reader()
for lon, lat in [[14.5, 46.5], [15, 47], [16, 48.5], [12.5, 47], [15.1, 48.]]:
ts = source_reader.read(lon, lat)
plt.plot(ts, label=f"Lon: {lon}, Lat: {lat}", marker='.')
plt.ylabel("SM [% sat.]")
plt.xticks(rotation=45)
plt.legend()
/var/folders/9c/7x6wf5fj0fbdvkxpnt4x2y7r0000gn/T/ipykernel_2618/2655621766.py:5: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
self.df = pd.read_csv(
[11]:
<matplotlib.legend.Legend at 0x152318470>

Output image stack
To create the image stack we need to decide:
The region of interest, i.e. the bounding box for which we create images and extract time series data for respectively. In our case we use the bounding box from the first Figure.
The pixel size we want to store the data on. Should be chosen according to the resolution of the time series grid and the area of interest (in the case of ASCAT it does not make much sense to transfer the global data to a regular grid, but for a regional subset it’s fine). In our case we use a target grid of 0.1° as visualised in the first Figure.
The temporal sampling of our image stack. Should also be chosen according to the temporal sampling of the time series data. This is a bit tricky because, as you can see when looking at the data in “assets/SM_AUT.csv” we have varying time stamps for different locations. But overall we expect that we don’t have more than 2 observations for each day (before and after 12 PM) and each point. So let’s start with a 12-hourly image stack.
Converter
The class to convert a time series data set into images is called Ts2Img and imported from repurpose.ts2img. We pass the above defined time series reader and create a regular target image grid object from the above defined dimensions. We allow up to 10 km for the nearest neighbour lookup between the target and source grid (remember that the source data is sampled at 12.5 km). We also pass the 12-hourly time stamps for which we create our images. Important: As we expect that there is a
difference in the time stamps we use in the image stack and the time stamps we get from the time series, we have to perform temporal collocation to match them. If we set time_collocation=False, it would be required that the same time stamps that we use in the image stack are also available in the time series data.
[12]:
from repurpose.ts2img import Ts2Img
from pygeogrids.grids import gridfromdims
target_grid = gridfromdims(x, y)
timestamps = pd.date_range('2010-06-01T00:00:00',
'2010-06-10T12:00:00', freq='12h')
converter = Ts2Img(ts_reader=source_reader,
img_grid=target_grid,
timestamps=timestamps,
variables=['sm'],
max_dist=10000,
time_collocation=True)
The .calc function will then start the conversion. First we split the passed time stamps into chunks of the selected size. This is relevant for large datasets that don’t fit into memory. In our small example case a single chunk is fine. Then we loop over all points in the image stack and look for the according time series (nearest neighbour with max distance). If a time series is found for a point, observations are written into the image stack, otherwise the fill value is kept. As this can be
quite time-consuming for large data sets, there is a keyword to activate parallel processing (when n_proc is chosen greater than 1).
Other arguments:
format_outto define whether you want to store one time stamp / single image in each netcdf file (slice) or the whole chunk (stack).fn_templateto set the file name of the output files (make sure that the {datetime} placeholder is included.drop_emptyto drop any empty images after conversion. This can be useful if you expect that there are many time stamps without data, and you want to save storage space (otherwise these files would contain only fill values).encodingto efficiently store data without wasting too much space, you can convert variable to a certain data type (e.g integers) and provide scale factors (precision when converting floats as integers for efficient storage). Common encoding keywords arescale_factor,add_offset,_FillValue,dtype(see also https://docs.xarray.dev/en/stable/user-guide/io.html#scaling-and-type-conversions)glob_attrsandvar_attrsnetcdf metadata included in each file and for certain variables.zlibto activate zlib compressionvar_fillvaluesandvar_dtypescan be used to force a certain value to use instead of NaN and convert to a different data type than the default float32. Note, it’s better to use the encoding keyword!
[13]:
from tempfile import mkdtemp
path_out = mkdtemp()
print(f"Images are stored in {path_out}")
glob_attrs = {'Description': 'ASCAT SSM resampled to regular 0.1 deg. grid'}
var_attrs = {'sm': {'unit': 'percent saturation', 'long_name': 'soil moisture'}}
encoding = {'sm': {'scale_factor': 0.01, 'dtype': 'int32', '_FillValue': -9999}}
converter.calc(path_out=path_out, format_out='slice',
fn_template='ascat_0.1deg_{datetime}.nc',
glob_attrs=glob_attrs, var_attrs=var_attrs,
encoding=encoding, img_buffer=100, n_proc=2,
drop_empty=True)
Images are stored in /var/folders/9c/7x6wf5fj0fbdvkxpnt4x2y7r0000gn/T/tmps6mtkrgj
Processed: 100%|██████████| 3/3 [00:01<00:00, 1.70it/s]
Processed: 100%|██████████| 14/14 [00:00<00:00, 236.58it/s]
Checking image
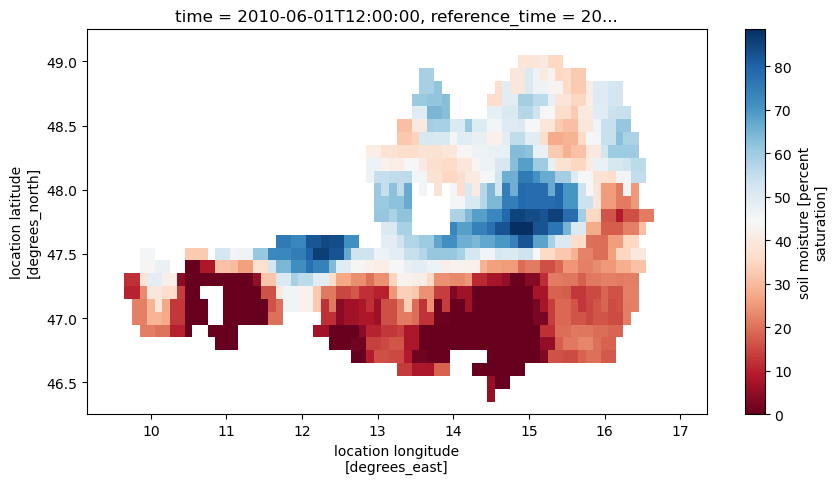
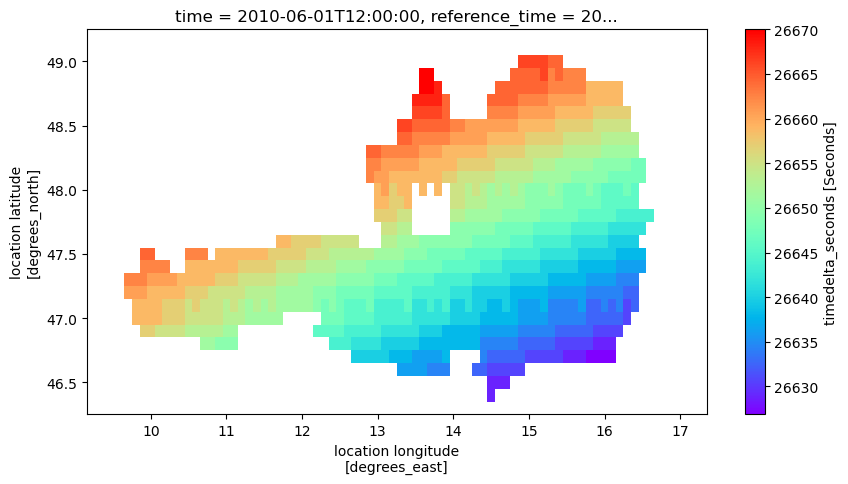
Looking at the so created images, we see that there is the expected variable sm in the files, but also a variable timedelta_seconds that contains the difference between the original time stamps and the time stamps assigned to the whole image. This way we can handle the slightly varying time stamps between location. Adding the offset to the image time stamp should therefore result in the same time that was originally in the time series.
[14]:
import xarray as xr
ds = xr.open_dataset(os.path.join(
path_out, "2010", "ascat_0.1deg_20100601120000.nc"))
ds['sm'].plot(figsize=(10,5), cmap='RdBu')
plt.figure()
ds['timedelta_seconds'].plot(figsize=(10, 5), cmap='rainbow')
[14]:
<matplotlib.collections.QuadMesh at 0x152374410>
<Figure size 640x480 with 0 Axes>
Let’s verify that we have the same values as in the time series. First we read a time series for a certain day and location. We find the same soil moisture and time stamp value in both data sets.
[15]:
ts = source_reader.read(14.5, 46.5).iloc[1]
print("Soil Moisture and time stamp in time series\n")
print(ts)
Soil Moisture and time stamp in time series
sm 5.64
Name: 2010-06-01 19:23:48.749991, dtype: float64
[16]:
from datetime import timedelta
img = ds.sel(lon=14.5, lat=46.5, method='nearest')
sm = img['sm'].values[0]
img_timestamp = pd.to_datetime(img['time'].values[0]).to_pydatetime()
timedelta = timedelta(seconds=float(img['timedelta_seconds'].values[0]))
print("Value and time stamp in image (after adding `timedelta_seconds` to the image wide time stamp\n")
print("sm:", sm)
print("timestamp+offset:", img_timestamp + timedelta)
Value and time stamp in image (after adding `timedelta_seconds` to the image wide time stamp
sm: 5.64
timestamp+offset: 2010-06-01 19:23:48.750000